
Bài 5. Kruskal-Wallis One-way ANOVA
Kiểm tra Kruskal-Wallis H (đôi khi còn được gọi là “ANOVA một chiều theo xếp hạng”) là một kiểm tra phi tham số dựa trên xếp hạng có thể được sử dụng để xác định xem có sự khác biệt có ý nghĩa thống kê giữa hai hoặc nhiều nhóm. Nó là phần mở rộng của bài kiểm tra Mann-Whitney U để cho phép so sánh nhiều hơn hai nhóm độc lập. Ví dụ: bạn có thể sử dụng bài kiểm tra Kruskal-Wallis H để biết liệu hiệu suất bài kiểm tra, được đo trên thang đo liên tục từ 0-100, có khác nhau dựa trên mức độ lo lắng của bài kiểm tra hay không (nghĩa là, biến phụ thuộc của bạn sẽ là “hiệu suất bài thi” và biến độc lập của bạn sẽ là “mức độ lo lắng khi kiểm tra”, có ba nhóm độc lập: sinh viên có mức độ lo lắng khi kiểm tra “thấp”, “trung bình” và “cao”). Ngoài ra, bạn có thể sử dụng bài kiểm tra Kruskal-Wallis H để hiểu liệu thái độ đối với sự phân biệt trả lương, trong đó thái độ được đo lường theo thang thứ tự, có khác nhau dựa trên vị trí công việc hay không (nghĩa là, biến phụ thuộc của bạn sẽ là “thái độ đối với sự phân biệt trả lương”, được đo lường trên thang điểm 5 từ “rất đồng ý” đến “rất không đồng ý” và biến độc lập của bạn sẽ là “mô tả công việc”, có ba nhóm độc lập: “nhân viên bán hàng”, “quản lý cấp trung” và “quản lý cao cấp”).
1. Khi nào sử dụng?
Một vấn đề nghiên cứu phổ biến là quyết định xem liệu sự khác biệt mẫu trong xu hướng trung tâm có phản ánh sự khác biệt thực sự trong các dân số bố mẹ hay không. Kiểm tra Kruskal-Wallis thường là thủ tục được lựa chọn để kiểm tra hai hoặc nhiều nhóm độc lập (trường hợp mẫu k) về sự bình đẳng vị trí khi các giả định về ANOVA một chiều – ‘one-way ANOVA’ (phân tích phương sai) bị nghi ngờ (tính không chuẩn và không đồng nhất của phương sai) hoặc khi các quan sát là tự nhiên ở dạng cấp bậc. Cơ sở lý thuyết nền tảng cho kiểm định này là nếu tất cả các điểm trong một nhóm ban đầu, được gán một giá trị xếp hạng, và các giá trị xếp hạng sau đó được phân bổ lại thành các nhóm độc lập (hoặc điều trị), thì theo giả thuyết vô hiệu về cơ hội tổng các thứ hạng trong mỗi nhóm sẽ giống nhau.
Các nhà nghiên cứu sử dụng bài kiểm tra này như một ANOVA một chiều để xác định xem liệu hai hay nhiều nhóm có các phân phối điểm giống nhau hay không. Bài kiểm tra Kruskal-Wallis không thay thế cho kiểm định tham số, mà là một công cụ quyết định bổ sung.
Kiểm định này cũng hữu ích để phân tích dữ liệu đếm trong các bảng phát sinh khi biến phản hồi là phân loại và thứ tự. Theo truyền thống, loại dữ liệu này được phân tích bằng kiểm định Chi-square, nhưng cần có có sự liên tục cơ bản đối với biến phản hồi, kiểm tra Kruskal-Wallis là một lựa chọn thay thế mạnh mẽ hơn kiểm tra r × k Chi-square.
2. Suy luận thống kê và giả thuyết vô hiệu
Giá trị thống kê kiểm định Kruskal-Wallis, H, nhạy cảm với sự thay đổi vị trí và theo giả thuyết vô hiệu (các dân số bằng nhau) là được phân phối (mẫu lớn) tiệm cận như Chi-bình phương với k-1 bậc tự do. Giả thuyết vô hiệu là các mẫu độc lập đến từ cùng một dân số hoặc từ các dân số có cùng giá trị trung vị (median). Giả thuyết thay thế không hướng là ít nhất một mẫu có trung vị khác với các mẫu khác. Giá trị lớn của thống kê kiểm định, H, dẫn đến việc bác bỏ giả thuyết vô hiệu.
Trong SPSS, kết quả đầu ra tự động cung cấp một giá trị xấp xỉ Chi-square. Nói chung, đầu ra SPSS đề cập đến phép xấp xỉ Chi-square, (chủ yếu dành cho các nghiên cứu mẫu lớn) dựa trên k-1 bậc tự do (k là số lượng mẫu hoặc nhóm độc lập). Vùng loại bỏ cho H0 kiểm định Kruskal-Wallis bao gồm tất cả các giá trị của χ2 lớn hơn (chẳng hạn χ2 với 2 df) với p = 0.05, tức là 5.99147 (Vui lòng xem bảng Phân phối χ2). Ví dụ một giá trị được tính toán, χ2 = 7.0404 vượt quá giá trị tới hạn (nằm trong vùng loại bỏ). Nếu thu được xác suất này nhỏ, dưới 5% (p<0.05), chúng ta có thể bác bỏ giả thuyết vô hiệu và kết luận rằng có sự khác biệt giữa các nhóm.
Chú ý rằng, nếu ít hơn 5 quan sát trong bất kì nhóm nào, một nhà nghiên cứu nên lo ngại về việc sử dụng xấp xỉ χ2 với các mẫu nhỏ, thì không nên sử dụng kiểm định này hoặc cần tính giá trị thống kê kiểm định H để có thể được đánh giá bằng cách sử dụng phân phối mẫu chính xác (mà tài liệu này không trình bày).
3. Giả định kiểm tra
Khi phân tích dữ liệu kiểm tra Kruskal-Wallis H, một phần của quy trình bao gồm việc kiểm tra để đảm bảo rằng dữ liệu đó phân tích thực sự có thể được phân tích bằng kiểm tra Kruskal-Wallis H không. Chúng ta cần làm điều này vì chỉ thích hợp sử dụng kiểm tra Kruskal-Wallis H nếu dữ liệu “vượt qua” các giả định được yêu cầu đối với kiểm tra Kruskal-Wallis H dưới đây để cung cấp cho bạn kết quả hợp lệ.
- Dữ liệu bao gồm các quan sát đã được chọn ngẫu nhiên từ một quần thể lớn vô hạn. Nói chung, biến độc lập nên bao gồm hai hoặc nhiều nhóm phân loại, độc lập. Thông thường, bài kiểm tra Kruskal-Wallis H được sử dụng khi bạn có ba hoặc nhiều nhóm phân loại, độc lập, nhưng nó có thể được sử dụng cho chỉ hai nhóm (tức là bài kiểm tra Mann-Whitney U được sử dụng phổ biến hơn cho hai nhóm). Ví dụ các biến độc lập đáp ứng tiêu chí này bao gồm dân tộc (ví dụ: ba nhóm: Da trắng, Mỹ gốc Phi và Tây Ban Nha), mức độ hoạt động thể chất (ví dụ: bốn nhóm: ít vận động, thấp, trung bình và cao), nghề nghiệp (ví dụ: năm nhóm: bác sĩ phẫu thuật, bác sĩ, y tá, nha sĩ, nhà trị liệu), v.v.
- (Các) dân số có phân phối liên tục cơ bản nhưng biến phản hồi là một phép đo thứ hạng (rank measurement) hoặc có thể chấp nhận mức độ liên tục (continuous level). Ví dụ về các biến thứ tự bao gồm thang đo Likert (ví dụ: thang điểm 7 từ “rất đồng ý” đến “hoàn toàn không đồng ý”), trong số các cách xếp hạng danh mục khác (ví dụ: thang đo 3 điểm giải thích mức độ thích một sản phẩm của khách hàng, từ “Không nhiều lắm”, đến “Cũng được”, đến “Có, rất nhiều”). Ví dụ về các biến liên tục bao gồm thời gian ôn tập (đo bằng giờ), trí thông minh (đo bằng điểm IQ), thành tích thi (đo từ 0 đến 100).
- Các quan sát là độc lập, có nghĩa là không có mối quan hệ nào giữa các quan sát trong mỗi nhóm hoặc giữa các nhóm với nhau. Ví dụ, phải có nhiều người tham gia khác nhau trong mỗi nhóm và không có người tham gia nào ở nhiều hơn một nhóm. Đây là một vấn đề thiết kế nghiên cứu nhiều hơn là một thứ bạn có thể kiểm tra, nhưng nó là một giả định quan trọng của bài kiểm tra Kruskal-Wallis H. Nếu nghiên cứu của bạn không đạt được giả định này, bạn sẽ cần sử dụng một bài kiểm tra thống kê khác thay cho bài kiểm tra Kruskal-Wallis H (ví dụ: kiểm tra Friedman).
- Tốt hơn là có ít nhất 4–5 đối tượng trong mỗi mẫu (nhóm độc lập) vì việc sử dụng xấp xỉ Chi-bình phương cho thống kê kiểm định H. Không nhất thiết phải có thiết kế cân đối (số lượng bằng nhau trong mỗi nhóm độc lập).
- Với sự không đồng nhất của phương sai, các phương sai khác nhau đối với các mẫu độc lập, có thể với quy trình kiểm định này để bác bỏ giả thuyết vô hiệu (bằng nhau của các trung vị), khi các trung bình trên thực tế là bằng nhau. Do đó, giá trị thống kê thử nghiệm có ý nghĩa, H, không đảm bảo sự khác biệt giữa các trung bình điều trị.
Vì kiểm tra Kruskal-Wallis H không giả định tính chuẩn mực trong dữ liệu và ít nhạy cảm hơn nhiều với các giá trị ngoại lệ, nên nó có thể được sử dụng khi các giả định này bị vi phạm và việc sử dụng ANOVA một chiều (one-way ANOVA) là không phù hợp. Ngoài ra, nếu dữ liệu của bạn là thứ tự (ordinal), ANOVA một chiều là không phù hợp, nhưng kiểm tra Kruskal-Wallis H thì không. Tuy nhiên, thử nghiệm Kruskal-Wallis H đi kèm với việc xem xét dữ liệu bổ sung dưới đây:
- Để biết cách giải thích kết quả từ bài kiểm tra Kruskal-Wallis H, chúng ta phải xác định xem liệu các phân phối trong mỗi nhóm (tức là, phân phối điểm cho mỗi nhóm của biến độc lập) có giống nhau không. Có thể xem sơ đồ dưới đây.
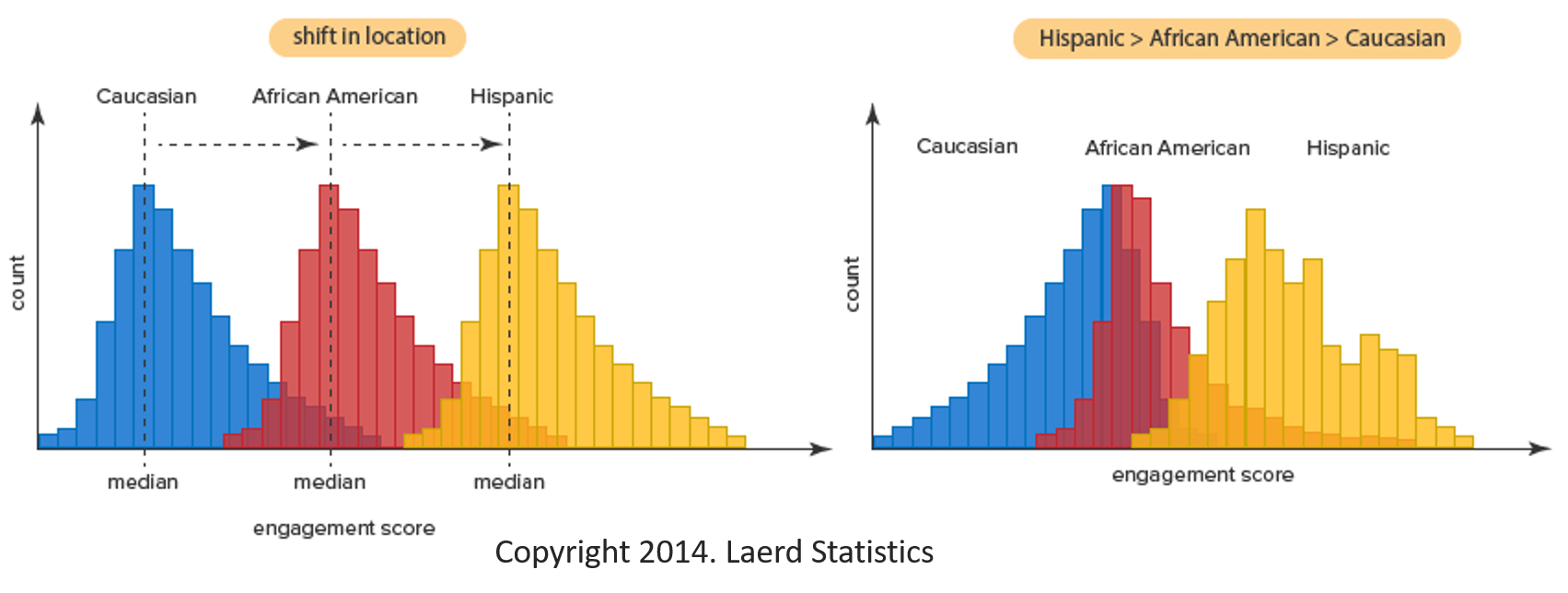
Trong sơ đồ bên trái ở trên, phân bố điểm của các nhóm “Da trắng” (Caucasian), “Người Mỹ gốc Phi” (African American) và “Tây Ban Nha” (Hispanic) có cùng hình dạng. Mặt khác, trong biểu đồ bên phải, sự phân bố điểm số cho mỗi nhóm không giống nhau (tức là chúng có hình dạng khác nhau). Nếu các bản phân phối có hình dạng giống nhau, chúng ta có thể sử dụng kiểm tra Kruskal-Wallis H để so sánh trung vị của biến phụ thuộc. Tuy nhiên, nếu các bản phân phối có hình dạng khác, chúng ta chỉ có thể sử dụng kiểm tra Kruskal-Wallis H để so sánh các cấp bậc trung bình (mean ranks). Việc có các bản phân phối tương tự chỉ đơn giản là cho phép bạn sử dụng các trung vị để thể hiện sự thay đổi trong vị trí giữa các nhóm. Do đó, điều rất quan trọng là phải kiểm tra giả định này nếu không chúng ta có thể diễn giải kết quả của mình không chính xác.
4. Thủ tục Kiểm tra Kruskal-Wallis One-way ANOVA
Thí dụ, một nhà nghiên cứu về tâm lí quan tâm đến việc cải thiện sức tập trung học tập của các sinh viên. Nhà nghiên cứu cho rằng liệu pháp Thiền có thể cải thiện sức tập trung học tập. Để điều tra điều này, nhà nghiên cứu tuyển 15 người tham gia (gồm 5 sinh viên ngành kỹ thuật, 5 sinh viên ngành xã hội và 5 sinh viên ngành tự nhiên) vào nghiên cứu của họ. Sau 4 tuần thực hiện Thiền trước học tập, những người tham gia được yêu cầu lại chỉ ra mức độ tập trung học tập trên thang từ 1 đến 10 điểm.
Nhà nghiên cứu muốn biết liệu có sự khác biệt giữa ba nhóm ngành sinh viên trong hiệu quả của liệu pháp thiền đến sức tập trung học tập hay không. Giả thuyết thay thế là ba nhóm khác biệt trong hiệu quả của liệu pháp thiền đến sức tập trung học tập. Alpha được thiết lập với 5% của ý nghĩa.
Các bước tính toán kiểm tra Kruskal-Wallis One-way ANOVA là:
- Kết hợp tất cả các điểm thành một nhóm và chỉ định một thứ hạng cho mỗi điểm thể hiện vị trí của nó trong chuỗi đơn.
- Mỗi giá trị được xếp hạng sau đó được gán lại cho nhóm tương ứng của nó (trong ví dụ này là nhóm ngành sinh viên kĩ thuật, tự nhiên và xã hội) và tổng các giá trị xếp hạng và giá trị trung bình được tính cho mỗi nhóm. Trong ví dụ này, số lượng mẫu trong mỗi nhóm là bằng nhau nhưng điều này là không cần thiết.
Kết quả tính toán được trình bày trong bảng 1 dưới đây:
Bảng 1
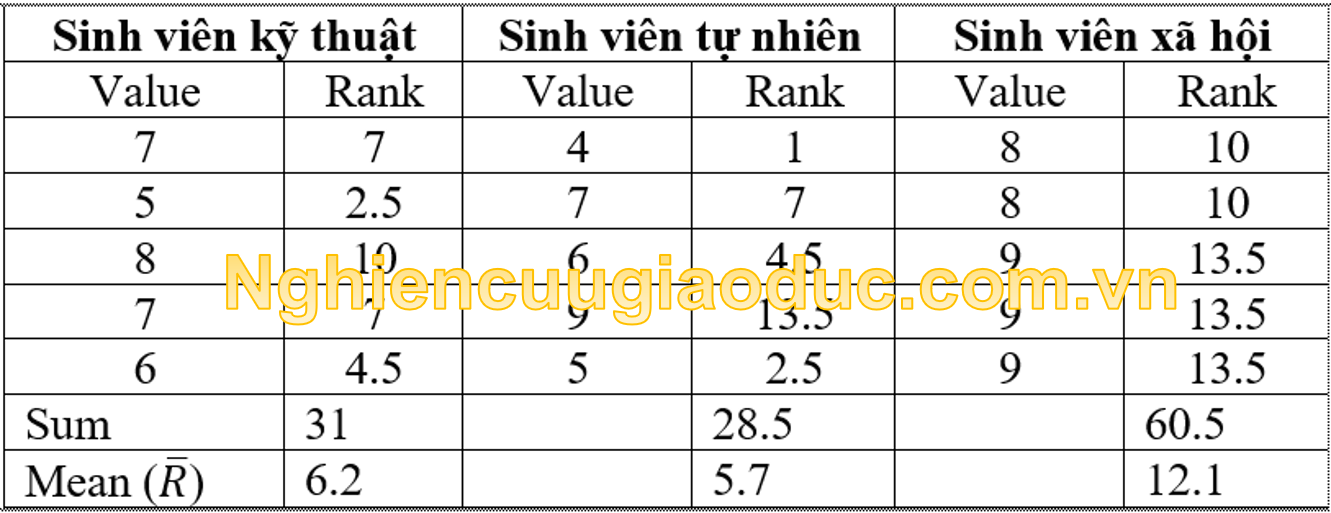
Sau đó, thống kê kiểm tra Kruskal-Wallis, H, được tính bằng công thức sau:
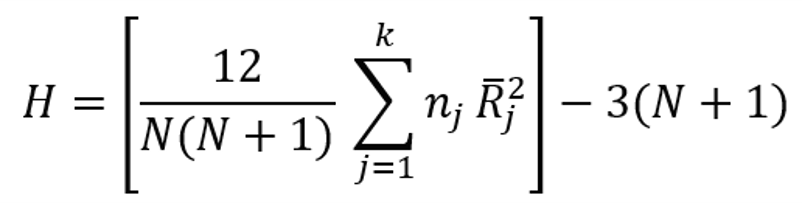
trong đó k là số nhóm (mẫu độc lập), nj là số quan sát trong nhóm thứ j, N là tổng số quan sát trong mẫu kết hợp và R trung bình là giá trị trung bình của các cấp trong nhóm thứ j.
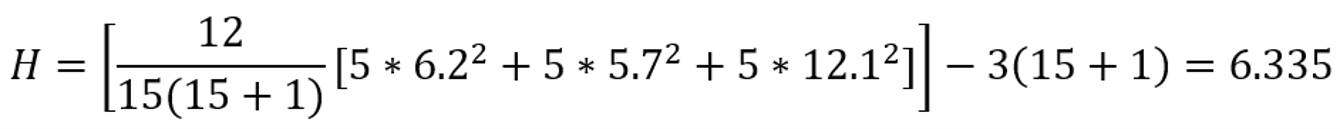
Như trong bài kiểm tra dấu hạng Wilcoxon, phương sai của phân phối mẫu của thống kê kiểm tra bị ảnh hưởng bởi sự bằng nhau giữa các điểm số bất kể các điểm bằng nhau thuộc về nhóm nào. Việc hiệu chỉnh cho sự bằng nhau được đưa ra bởi công thức:
![]()
trong đó, g là số nhóm các giá trị bằng nhau, ti là số lượng của các thứ hạng bằng nhau trong mỗi nhóm của các giá trị bằng nhau, N là tổng số quan sát trong mẫu kết hợp. Thống kê Kruskal-Wallis H sau đó được chia cho hệ số hiệu chỉnh này.
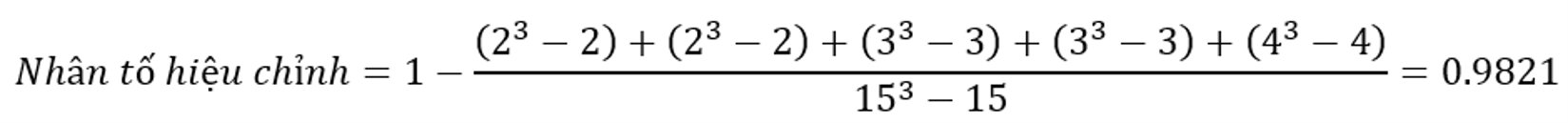
Giá trị H điều chỉnh cho các số bằng nhau: 6.335/0.9821=6.4502
Nhận xét: Khi bất kỳ nhóm độc lập nào có ít hơn năm quan sát, chúng ta có thể mô tả đây là một thiết kế mẫu nhỏ. Trong tình huống này, chúng ta sử dụng phân phối mẫu chính xác (exact sampling distribution) của thống kê kiểm tra H. Điều này được thể hiện trong Bảng dưới đây (chỉ dành cho 3 nhóm độc lập):
Bảng 2: Các giá trị tới hạn của kiểm tra Kruskal-Wallis H
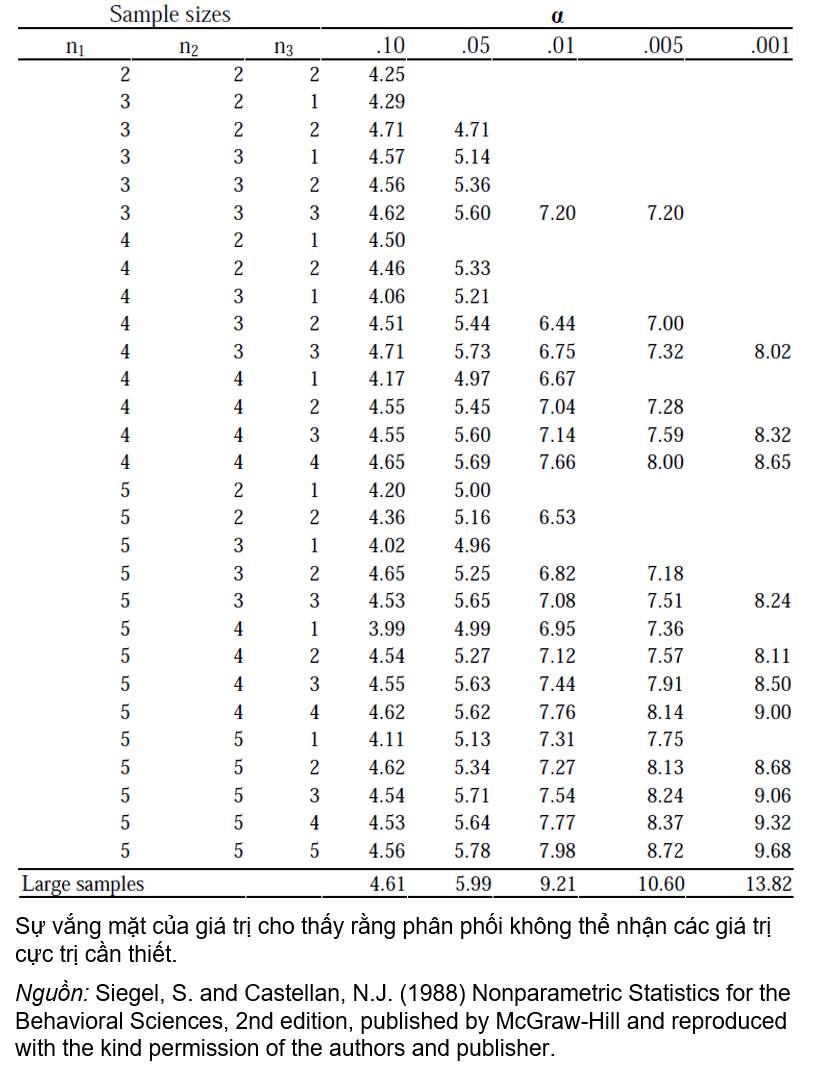
Trong ví dụ này, chúng ta đã chọn alpha là 0.05. Giá trị tới hạn cho H với alpha = 0.05 và n1 = n2 = n3 = 5 là 5.78. Vùng loại bỏ giả thuyết H0 bao gồm tất cả các giá trị H> 5.78. Vì H quan sát được lớn hơn giá trị tới hạn, 6.4502>5.78, nên xác suất thu được giá trị H lớn bằng 6.4502, khi giả thuyết vô hiệu là đúng, bằng hoặc nhỏ hơn p = 0.05. Chúng ta bác bỏ giả thuyết vô hiệu ở mức 5% và kết luận rằng có đủ bằng chứng về sự khác biệt giữa ba nhóm sinh viên (kỹ thuật, tự nhiên và xã hội) về hiệu ứng của Thiền để cải thiện sức tập trung học tập.
Khi H được tìm thấy là có ý nghĩa thống kê, điều đó chỉ ra rằng k mẫu không đến từ cùng một dân số, tức là ít nhất một trong các mẫu có trung vị khác với ít nhất một trong các mẫu khác. Thống kê H không cung cấp thông tin về cái nào hoặc bao nhiêu mẫu khác nhau đáng kể. Khi số lượng phép so sánh nhỏ, phép thử Mann-Whitney U có thể được sử dụng cho phân tích post hoc theo sau phép thử Kruskal-Wallis H có ý nghĩa thống kê và điều chỉnh mức ý nghĩa của p. Hoặc kiểm tra post hoc so sánh đa cặp (pairwise multiple-comparison) nên được thực hiện.
Khi số lượng quan sát trong các nhóm độc lập vượt quá 5 thì thống kê kiểm định H được xấp xỉ bằng phân phối Chi-bình phương với k − 1 bậc tự do (k là số mẫu hoặc nhóm độc lập). Kết quả thường được cung cấp trong các gói phần mềm thống kê, chẳng hạn SPSS.
















