
Bài 2. Hồi quy Logistic đa thức (Multinomial Logistic Regression)
Đọc kết quả:
Nói chung, hồi quy logistic đa thức chạy ra khá nhiều bảng, nhưng chúng ta có thể cần quan tâm những bảng chính dưới đây:

Bảng Goodness-of-Fit cung cấp các thông tin để giả thích độ phù hợp của dữ liệu so với mô hình tổng thể. Dòng đầu tiên Pearson thể hiện kết quả kiểm tra Chi-bình phương. Giá trị Chi-square càng lớn thì mô hình càng kém phù hợp. Nếu sig.<5% thì chắc chắn mô hình thu được là không phù hợp với dữ liệu này. Trong ví dụ này, cột giá trị sig.cho biết p=0.429>5%, do đó không có ý nghĩa thống kê, nên mô hình hồi quy tổng thể phù hợp với dữ liệu. Hàng còn lại của bảng (tức là hàng Độ lệch “Deviance“) trình bày thống kê Chi-bình phương Độ lệch. Hai thước đo mức độ phù hợp này có thể không phải lúc nào cũng cho kết quả giống nhau.

Một tùy chọn khác để kiểm tra thước đo tổng thể về mô hình là xem xét các thống kê được trình bày trong bảng Model Fitting Information. Hàng “Final” trình bày thông tin về việc liệu tất cả các hệ số của mô hình có bằng 0 hay không (tức là bất kỳ hệ số nào có ý nghĩa thống kê hay không). Một cách khác để diễn giải kết quả này là liệu các biến mà bạn đã thêm vào có cải thiện đáng kể về mặt thống kê so với một mình biến chặn hay không (tức là không có biến nào được thêm vào). Bạn có thể thấy giá trị cột “Sig.” rằng p = 0.003 < 0.05, có nghĩa là mô hình đầy đủ dự đoán có ý nghĩa thống kê về biến phụ thuộc tốt hơn so với mô hình chỉ một mình điểm chặn (intercept-only model).

Trong hồi quy logistic đa thức, bạn cũng có thể xem xét các số đo tương tự như R2 trong hồi quy tuyến tính bình phương nhỏ nhất thông thường. Tuy nhiên, trong hồi quy logistic đa thức, đây là các số đo R2 giả và có nhiều hơn một, mặc dù không có giá trị nào có thể diễn giải dễ dàng. Tuy nhiên, chúng được tính toán và hiển thị bên dưới trong bảng Pseudo R-Square. Thống kê SPSS tính toán các phép đo giả R2 với Cox và Snell, Nagelkerke và McFadden.
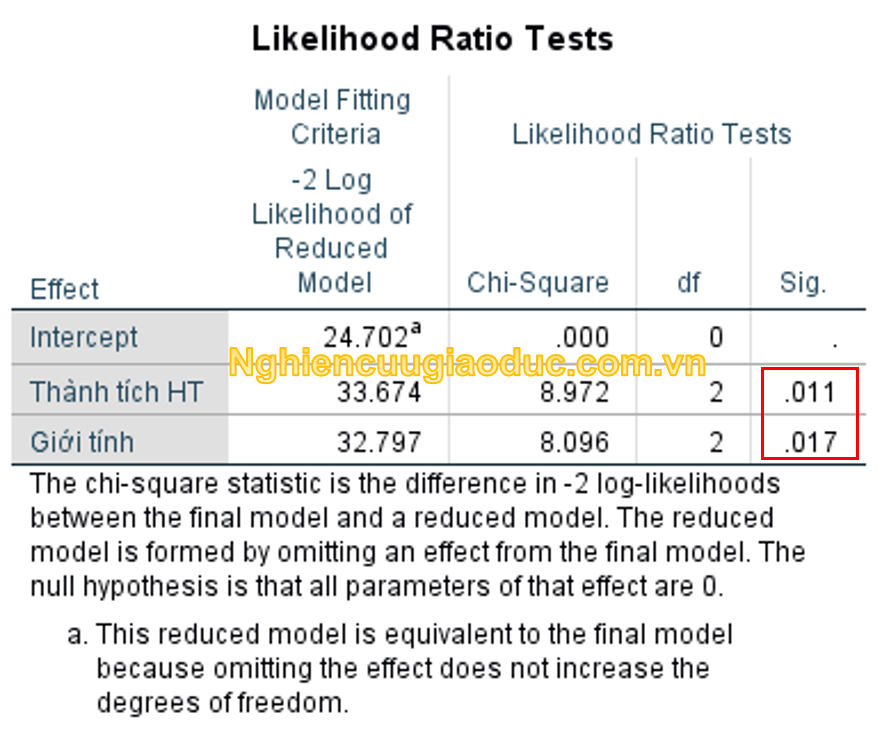
Có tầm quan trọng lớn hơn là các kết quả được trình bày trong bảng Likelihood Ratio Tests. Nói chung, bảng này cho ta thấy các biến độc lập có tác động có ý nghĩa thống kê đến biến phụ thuộc hay không? Bạn có thể thấy rằng cả biến ‘Thành tích học tập’ (p=0.011 < 0.05) và ‘Giới tính’ (p = 0.017 < 0.05) là có ý nghĩa thống kê (tức là có tác động đến biến phụ thuộc). Thường không có bất kỳ sự quan tâm nào đến điểm chặn mô hình (tức là hàng Điểm chặn “Intercept“). Thật ra bảng này chỉ hữu ích khi đánh giá cho biến phân loại, vì đây là bảng duy nhất cho thấy tác động chung của biến phân loại (tức là biến ‘Giới tính’). Còn những ước lượng tham số cụ thể được trình bày trong bảng Ước lượng tham số (Parameter Estimates) như hình bên dưới:
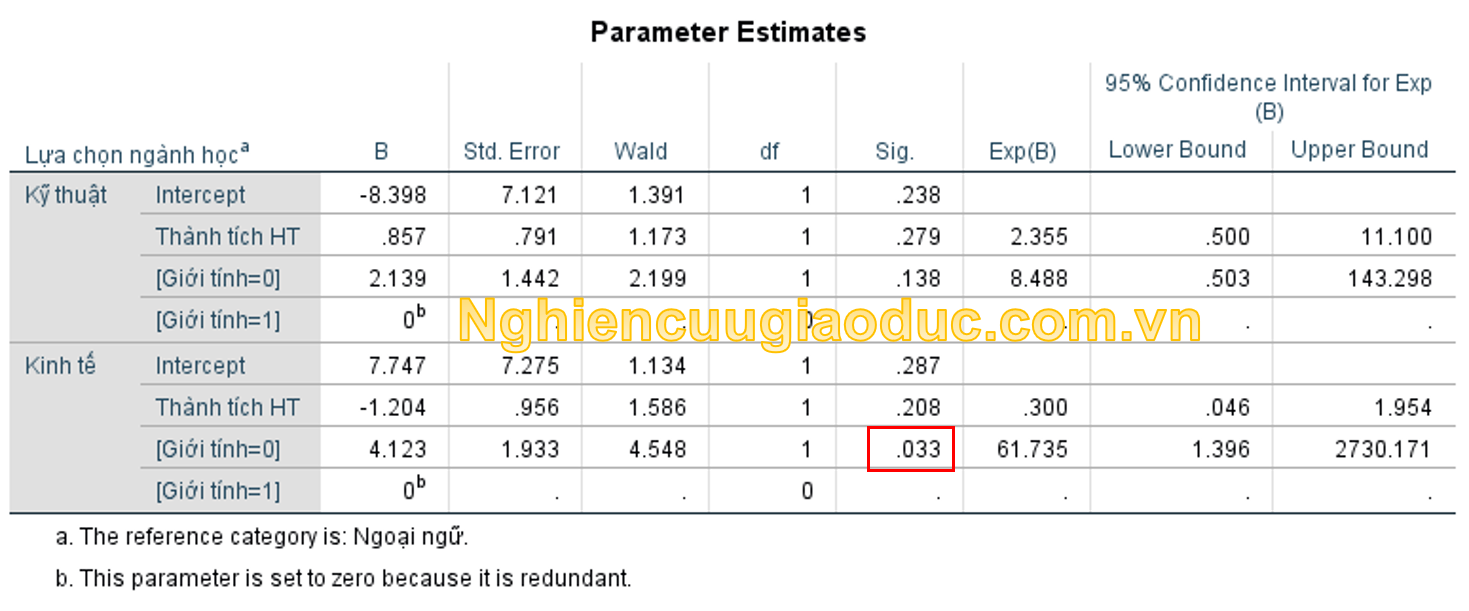
Bảng này trình bày các ước lượng tham số (còn được gọi là các hệ số của mô hình). Như bạn có thể thấy, mỗi biến giả (dummy variable) có một hệ số cho biến ‘Giới tính’. Tuy nhiên, đó không là giá trị ý nghĩa thống kê tổng thể. Điều này đã được trình bày trong bảng trước (tức là bảng Likelihood Ratio Tests). Vì có hai loại của biến phụ thuộc, bạn có thể thấy rằng có hai bộ hệ số hồi quy logistic (đôi khi được gọi là hai logit). Tập hợp hệ số đầu tiên được tìm thấy trong hàng “Kỹ thuật” (đại diện cho sự so sánh của mục ‘Kỹ thuật’ với danh mục tham chiếu ‘Ngoại ngữ’). Bộ hệ số thứ hai được tìm thấy trong hàng “Kinh tế” (đại diện cho sự so sánh của mục ‘Kinh tế’ với mục tham chiếu ‘Ngoại ngữ’). Bạn có thể thấy rằng biến “ThanhtichHT” cho cả hai bộ hệ số là không có ý nghĩa thống kê (p = .279 và p = .208, tương ứng với giá trị tại cột “Sig.“).
1. Khi nào sử dụng?
Mô hình hồi quy logistic nhị thức được sử dụng để dự đoán một biến phụ thuộc lưỡng phân (ví dụ, có/ không, đạt/ không đạt) bởi một hoặc nhiều biến độc lập liên tục hoặc phân loại.
Phương trình liên hệ có dạng (logarit Odds):
Mô hình hồi quy đa thức (còn được g . . .
This content is restricted to subscribers
| * Lưu ý: Bạn sẽ không thể đọc tài liệu nếu bạn chưa trả phí hoặc gói tài liệu trả phí của bạn đã hết hạn. Vui lòng đăng ký tài khoản Premium tại đây. |
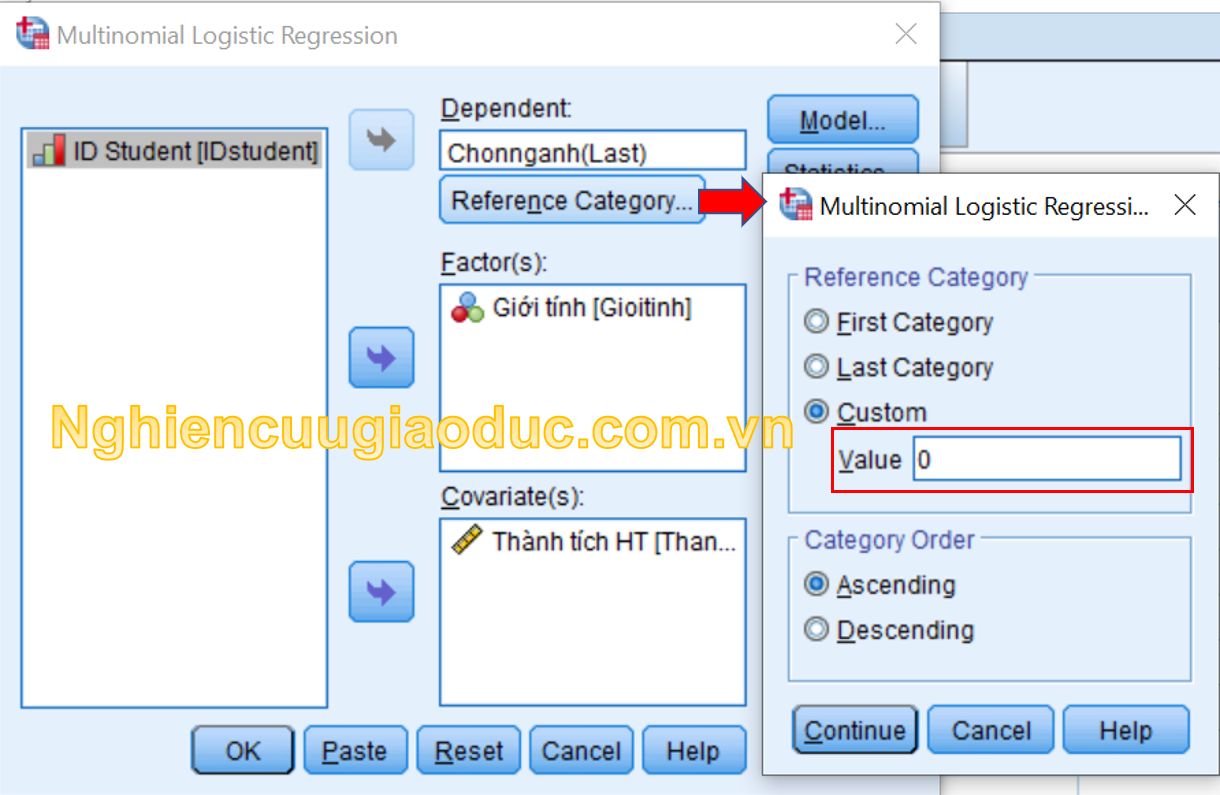
Về ý tưởng, bảng Parameter Estimates là kết quả so sánh giữa nhóm Kỹ thuật, và nhóm Kinh tế với nhóm tham chiếu cơ sở là Ngoại ngữ. Việc chọn nhóm tham chiếu cơ sở nào là do mình tự quyết định. Cuối cùng, còn việc so sánh giữa nhóm ‘Kỹ thuật’ và nhóm ‘Kinh tế’ như thế nào. Lúc này ta cần thực hiện chạy lại hồi quy đa thức, với nhóm tham chiếu là nhóm ‘Kỹ thuật’ hoặc ‘Kinh tế’. Giả sử chọn nhóm tham chiếu là ‘Kỹ thuật’, lúc đó chương trình sẽ chạy ra lấy nhóm Kỹ thuật so với nhóm Kinh tế, và nhóm Kỹ thuật so với nhóm Ngoại ngữ. Việc chọn nhóm tham chiếu bằng cách nhấn nút Reference Category và điền vào số mình cần làm tham chiếu như trong hình (nhập giá trị 0 = Kỹ thuật).
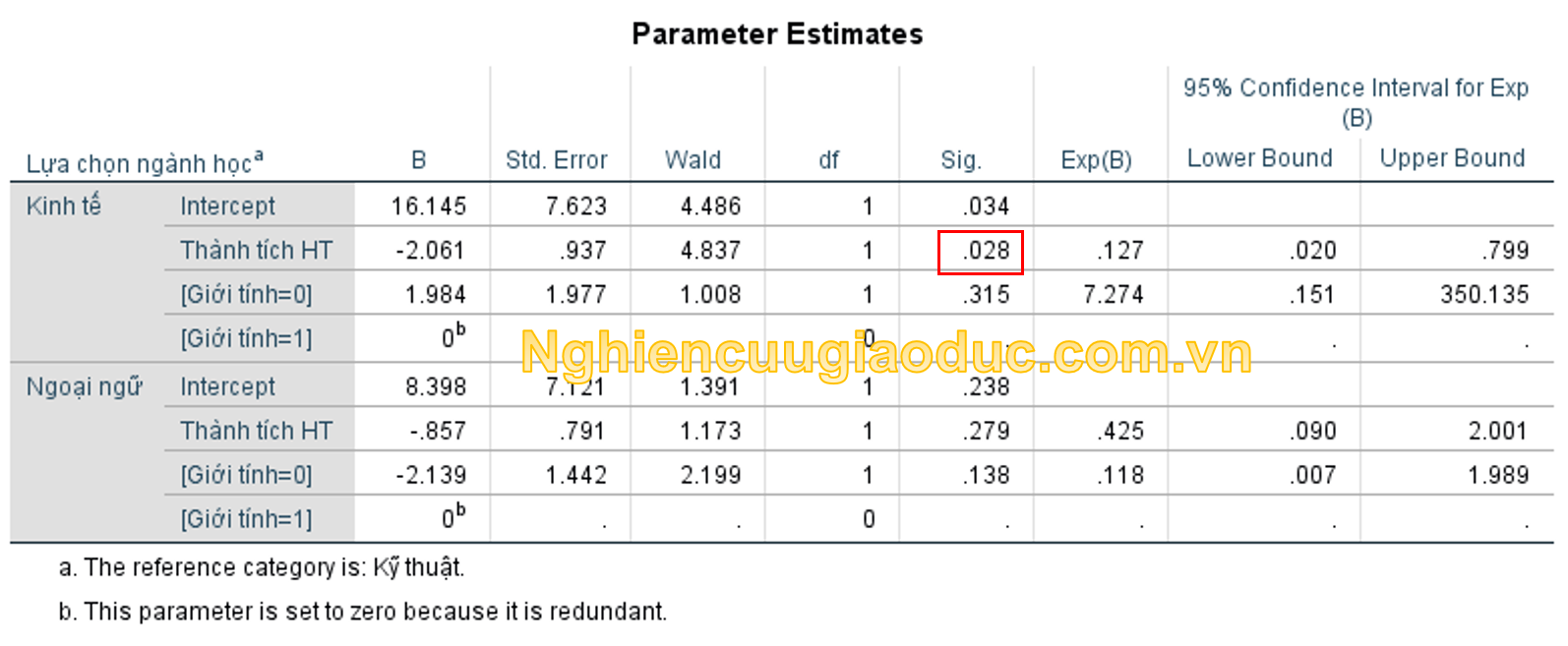
Việc phân tích bảng Parameter Estimates tương tự như bên trên.
1. Khi nào sử dụng?
Mô hình hồi quy logistic nhị thức được sử dụng để dự đoán một biến phụ thuộc lưỡng phân (ví dụ, có/ không, đạt/ không đạt) bởi một hoặc nhiều biến độc lập liên tục hoặc phân loại.
Phương trình liên hệ có dạng (logarit Odds):
Mô hình hồi quy đa thức (còn được g . . .
This content is restricted to subscribers
| * Lưu ý: Bạn sẽ không thể đọc tài liệu nếu bạn chưa trả phí hoặc gói tài liệu trả phí của bạn đã hết hạn. Vui lòng đăng ký tài khoản Premium tại đây. |
















